
Ondanks de snelle groei van AI-onderzoek in de gezondheidszorg, blijft de toepassing ervan in de praktijk aanzienlijk achter bij andere sectoren. Om deze kloof te dichten heeft een groep onderzoekers van de Universiteit voor Toegepaste Wetenschappen en Kunsten Noordwest Zwitserland, ETH Zürich en de Universiteit van Bern 'AI for IMPACTS' voorgesteld - een raamwerk dat is ontworpen om te beoordelen in hoeverre AI klaar is voor toepassing in de gezondheidszorg.
Integratie wordt nog steeds belemmerd door tal van uitdagingen, waaronder vertrouwenskwesties, zorgen over nauwkeurigheid en betrouwbaarheid, problemen met het reproduceren van resultaten en een complex web van ethische, juridische en maatschappelijke implicaties. Hoewel er verschillende kaders zijn ontwikkeld om AI in de gezondheidszorg te evalueren, is er nog steeds een kritieke kloof: een allesomvattende, systematische aanpak die niet alleen de werkelijke impact beoordeelt, maar ook duidelijke richtlijnen biedt voor klinische implementatie, monitoring, inkoop en evaluatie.
Om deze kritieke kloof te overbruggen, introduceert het “AI for IMPACTS Framework for Evaluating the Long-Term Real-World Impacts of AI-Powered Clinician Tools”, gepubliceerd in JMIR, een uitgebreide aanpak die verder gaat dan traditionele klinische studies. Dit raamwerk voorziet in de dringende behoefte aan een robuust, systematisch hulpmiddel om te beoordelen of AI klaar is voor toepassing in de echte wereld van de gezondheidszorg en biedt een gestructureerd pad voor implementatie, integratie en monitoring.
Een andere kijk op AI-evaluatie
Ondanks de snelle vooruitgang van AI in de gezondheidszorg schieten bestaande evaluatiebenaderingen op verschillende cruciale gebieden tekort, wat een zinvolle integratie in de klinische praktijk in de weg staat. De belangrijkste uitdagingen zijn onder andere:
Verouderde beoordelingskaders: Traditionele technologie-evaluaties houden vaak geen rekening met de dynamische en evoluerende aard van AI in de gezondheidszorg. Traditionele HTA kaders missen het aanpassingsvermogen dat nodig is om de unieke uitdagingen van AI, de complexiteit in de echte wereld en de impact op de lange termijn te beoordelen.
Gebrek aan gestandaardiseerde evaluatie naast klinische proeven: Hoewel er verschillende rapportagekaders bestaan voor klinische proeven, is er geen wereldwijd geaccepteerde standaard voor de beoordeling van AI-instrumenten buiten gecontroleerde onderzoeksomgevingen. Zonder een uniform, alomvattend kader blijft de toepassing van AI gefragmenteerd en is er geen duidelijk pad van ontwikkeling naar praktische implementatie.
Blinde vlekken in de regelgeving: Goedkeuringen door de regelgevende instanties, zoals de FDA-goedkeuringen en opkomende wetten zoals de EU AI Act, zijn bedoeld om de veiligheid en betrouwbaarheid van AI-gestuurde hulpmiddelen in de gezondheidszorg te garanderen. Er zijn echter nog steeds belangrijke hiaten; een recent onderzoek toonde aan dat bijna de helft van de door de FDA goedgekeurde AI-apparaten niet beschikt over klinische validatiegegevens, waardoor bezorgdheid ontstaat over hun effectiviteit in de echte wereld en mogelijke risico's voor de patiëntenzorg.
Implementatie uitdagingen: Bestaande richtlijnen gaan grotendeels voorbij aan het complexe, uit meerdere fasen bestaande proces dat nodig is om AI naadloos te integreren in klinische workflows. Dit resulteert in beperkte richtlijnen voor het schalen, ondersteunen en monitoren van AI-tools nadat ze zijn geïmplementeerd.
Te veel vertrouwen in technische maatstaven: De evaluatie van AI in de gezondheidszorg wordt nog steeds gedomineerd door traditionele prestatie-indicatoren zoals gevoeligheid en specificiteit. Hoewel deze indicatoren belangrijk zijn, slagen ze er niet in om bredere klinische resultaten, bruikbaarheid en langetermijneffecten op de patiëntenzorg vast te leggen.
Om het potentieel van AI in de gezondheidszorg echt te benutten, moeten we verder gaan dan gefragmenteerde, proefgerichte evaluaties en een uitgebreid kader opstellen dat niet alleen de prestaties van AI meet in gecontroleerde omgevingen, maar ook de toepassing in de echte wereld, de klinische impact en de duurzaamheid op de lange termijn beoordeelt. De volgende stap is duidelijk: heroverwegen hoe we AI evalueren om ervoor te zorgen dat het tastbare, blijvende voordelen oplevert voor zowel zorgverleners als patiënten.
Een instrument om te beoordelen of AI klaar is voor toepassing in de gezondheidszorg
Door systematisch bestaande beoordelingskaders te beoordelen en de belangrijkste bevindingen samen te vatten, hebben de auteurs van deze studie een uitgebreid kader ontwikkeld dat verder gaat dan de traditionele evaluatiebenaderingen, die zich vaak beperken tot technische meetgegevens of methodologieën op studieniveau. In plaats daarvan worden kritieke realistische implementatiefactoren en de klinische context meegenomen, waardoor een meer holistische en praktische benadering wordt geboden voor het beoordelen van AI-tools in de gezondheidszorg.
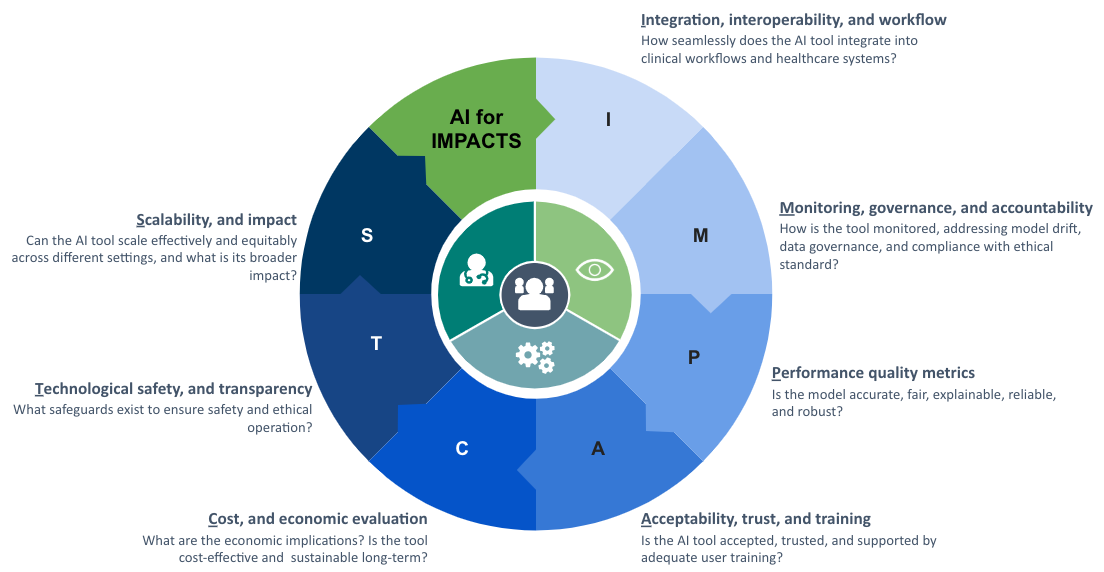
Met een sterke nadruk op het meten van de langetermijneffecten van AI-technologieën in de echte wereld, introduceerden de auteurs het AI for IMPACTS-raamwerk. De beoordelingscriteria zijn onderverdeeld in zeven domeinen, die elk een cruciaal aspect van de toepassing van AI in de gezondheidszorg vertegenwoordigen:
I - Integratie, interoperabiliteit en workflow
M - Monitoring, bestuur en verantwoording
P - Prestatie- en kwaliteitsmaatstaven
A - Aanvaardbaarheid, vertrouwen en opleiding
C - Kosten en economische evaluatie
T - Technologische veiligheid en transparantie
S - Schaalbaarheid en impact
Deze zeven dimensies worden verder onderverdeeld in 28 specifieke subcriteria, waardoor een gestructureerd maar aanpasbaar instrument ontstaat voor de evaluatie van AI in het complexe landschap van de gezondheidszorg. Een cruciale uitdaging bij AI-beoordeling is echter het gebrek aan multidisciplinaire expertise onder beoordelaars. Veel belanghebbenden die betrokken zijn bij AI-evaluatie missen de benodigde training, terwijl traditionele evaluatiemethoden moeite hebben om gelijke tred te houden met de snelle ontwikkelingen van AI. Om een verantwoorde en effectieve integratie van AI in de gezondheidszorg te waarborgen, moeten beoordelingsprocessen dynamischer, flexibeler en responsiever worden, waarbij een balans moet worden gevonden tussen strenge beoordelingsnormen en de flexibiliteit die nodig is om zich aan te passen aan het veranderende landschap van AI.
De dringende behoefte aan een uitgebreide aanpak
“Onze grondige evaluatie van AI-beoordelingsstudies heeft significante methodologische hiaten aan het licht gebracht, waaronder ontbrekende of onvoldoende gedetailleerde delen over de methoden, een gebrek aan analytische nauwkeurigheid en minimale validatie in de praktijk waarbij de belangrijkste belanghebbenden betrokken zijn”, legt Christine Jacob, projectleider en eerste auteur van het onderzoek, uit. “Deze tekortkomingen kunnen de geloofwaardigheid en relevantie van bestaande evaluatiekaders ondermijnen en versterken de dringende behoefte aan een uitgebreidere, door belanghebbenden gestuurde aanpak.”
Om dit aan te pakken is het onderzoeksteam actief op zoek naar partners en financiering om de validatie van het AI for IMPACTS-kader te ondersteunen. Het doel is om consensus te bereiken onder belanghebbenden over een robuust AI-beoordelingsinstrument dat een balans biedt tussen de uiteenlopende en soms tegenstrijdige prioriteiten van de belangrijkste spelers in het ecosysteem van de gezondheidszorg.









